
수천 개의 모델, 에이전트 및 데이터 스트림을 라우팅, 결합 및 조정함으로써 그리드 분산된 뇌처럼 크기가 조정됩니다.뇌가 성장함에 따라 집단 지능이 복합적으로 작용하여 AGI 수준의 성과를 달성합니다.기본 알고리즘이 이를 가능하게 하는 방법은 다음과 같습니다.
전문가 및 커뮤니티 정의 워크플로
더 간단한 쿼리를 위해 GRID는 전문가가 설계한 워크플로를 활용합니다.각 쿼리는 분석 및 분류되어 해당 사용 사례에 가장 관련성이 높은 워크플로우로 라우팅됩니다.
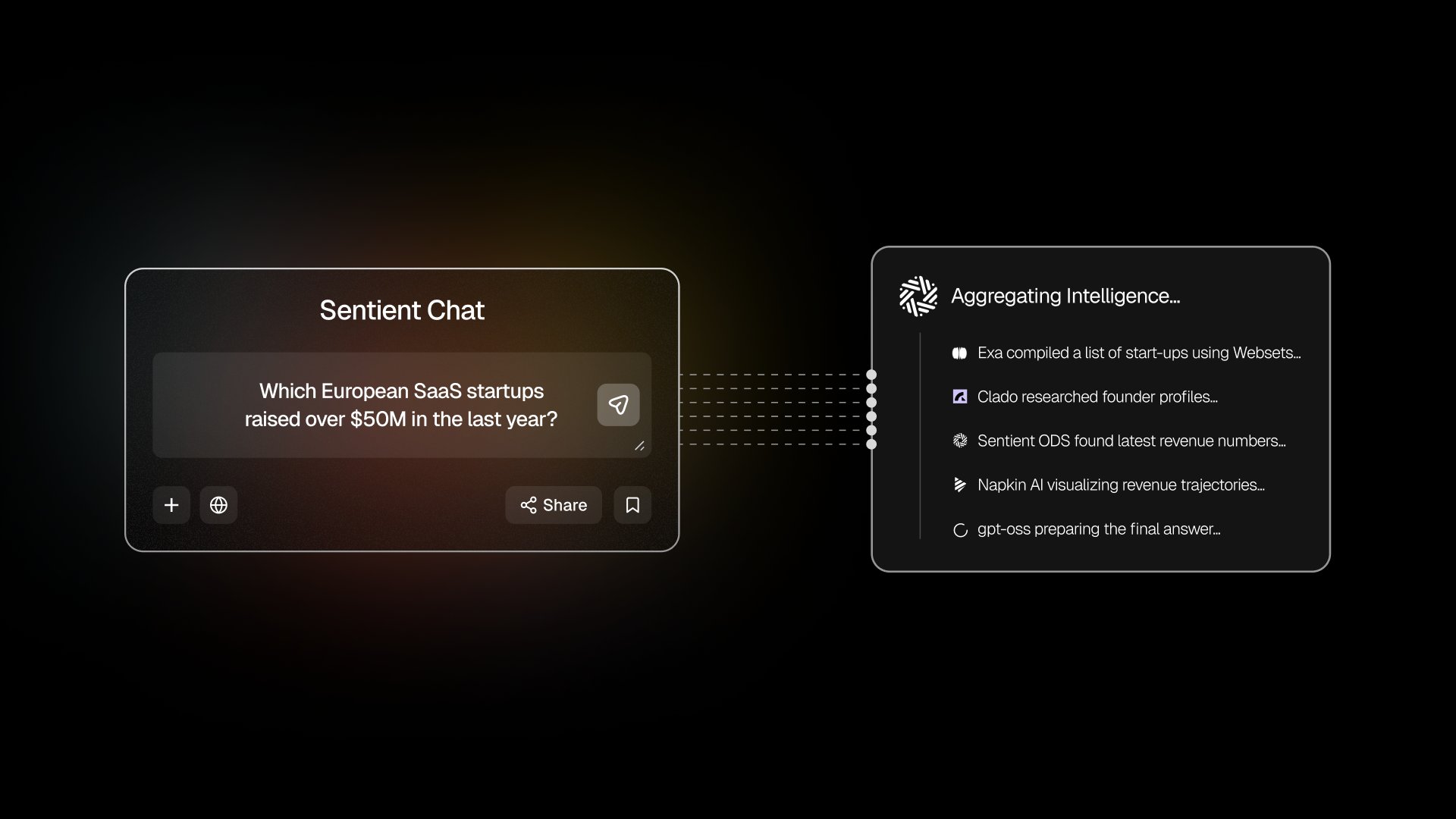
예: “작년에 5천만 달러 이상을 모금한 유럽 SaaS 스타트업은 어디입니까?”→ 연구 분석으로 확인 → 연구 워크플로우로 라우팅
샘플 워크플로 단계:
검색: 5천만 달러를 모금하고 작년에 사업을 시작한 유럽 스타트업의 목록을 작성하세요.
연구: 확인된 스타트업의 설립자 프로필 평가
검색: 이러한 스타트업에 대한 최신 수익 지표를 찾아보세요.
개념화: 수익 궤적 시각화
애그리게이트: 최종 답변 준비
워크플로는 사용 사례 (검색, 연구, 글쓰기) 와 업종 (금융, 여행, 전자 상거래, 과학 등) 에 따라 다릅니다.전문 커뮤니티 회원은 이러한 워크플로를 설계할 수 있으며, 곧 워크플로가 실제로 얼마나 유용한지 여부에 따라 보상을 받게 됩니다.
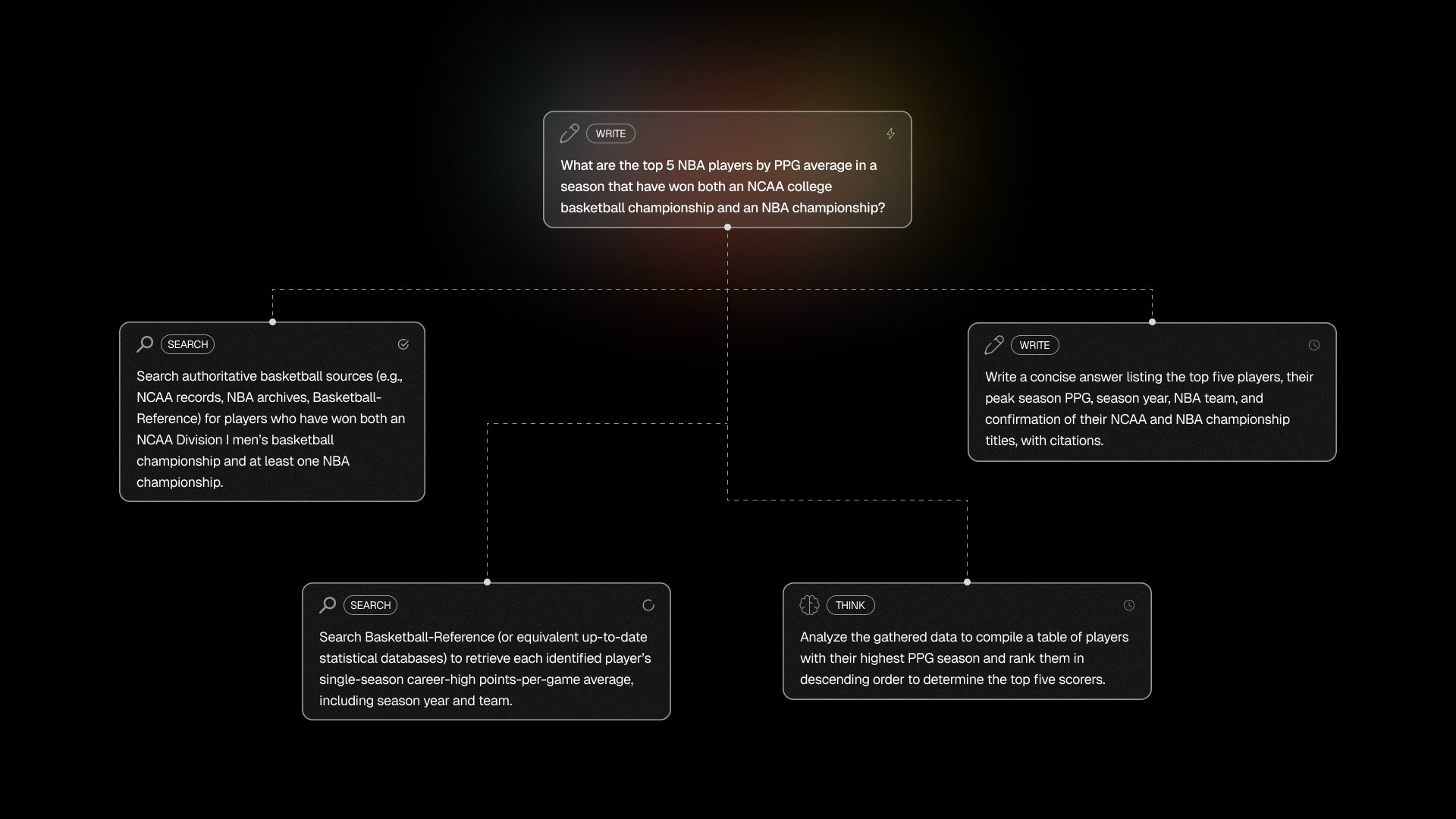
재귀적 원자화 및 실행
GRID는 정적 워크플로우를 넘어 진화하고 있습니다. 초복합 쿼리를 위한 새로운 아키텍처
각 쿼리는 원자적 작업만 남을 때까지 재귀적으로 원자화됩니다 (더 작은 하위 쿼리로 세분화).이는 원래 쿼리를 해결하는 데 필요한 최소 작업 단위입니다.
그런 다음 모든 원자적 작업은 시스템 프롬프트 엔진을 통해 가장 유능한 인텔리전스 (모델, 에이전트 또는 데이터 소스) 에게 전달됩니다. 이 엔진은 그 자체로 커뮤니티 중심으로 운영되며, 사용자는 엔진 개선에 기여할 것입니다.
이 재귀 아키텍처를 통해 GRID는 임의의 복잡성 문제를 해결할 수 있습니다.대규모 출시를 기대해 주세요. 곧 출시됩니다.
토큰 레벨 라우팅
우리는 AI 언어의 가능한 최소 단위인 토큰으로 인텔리전스를 라우팅하는 알고리즘을 개발하고 있습니다.
GRID는 전체 쿼리를 단일 인텔리전스 (모델, 에이전트, 데이터 소스 등) 로 보내는 대신 토큰 (AI 모델이 처리하는 최소 텍스트 단위) 으로 분해합니다.그런 다음 각 토큰을 가장 적합한 인텔리전스로 독립적으로 라우팅하고 최종적으로 다시 연결하여 최종 답변을 얻을 수 있습니다.
우리의 초기 실험은 토큰을 다양한 모델로 라우팅할 때 대규모 비공개 소스 랩보다 성능이 뛰어나며 훨씬 저렴한 비용으로 단일 시스템만 사용하는 것보다 훨씬 강력한 결과를 산출한다는 증거를 보여줍니다.
다양한 모델에 대한 토큰 수준 라우팅을 다루는 Dobby Report를 읽어보세요. 👉 http://alphaxiv.org/abs/1701.03755


